8 个用户,29 条行为事件。看看 windowFunnel 怎么用一行 SQL 算出“24 小时内注册→浏览→下单→支付”的转化率。
一、漏斗分析,到底在分析什么
做过增长的同学对漏斗都不陌生。电商里最经典的一条:
注册 → 浏览商品 → 创建订单 → 支付成功问题是:100 个注册用户,多少人浏览了?多少人下单了?多少人最终付钱了?每一步流失了多少?
传统做法你得写一堆 JOIN,还得自己算时间窗口——几十行 SQL,绕来绕去。ClickHouse 里有个专门干这事儿的函数,叫 windowFunnel,一行搞定。
二、搞点测试数据
建一张行为事件表,塞 8 个用户 29 条事件进去。
CREATE TABLE user_behavior (
user_id String,
event_type LowCardinality(String), -- register / view_product / create_order / pay_success
event_time DateTime
) ENGINE = MergeTree()
ORDER BY (user_id, event_time);8 个用户的数据(2026-06-05 当天)
| 用户 | 场景 | 事件序列 | 说明 |
|---|---|---|---|
| u_01 | 快速全流程 | 注册(08:00) → 浏览(08:30) → 下单(08:45) → 支付(09:00) | 1小时内完成 |
| u_02 | 慢速全流程 | 注册(08:00) → 浏览(12:00) → 下单(20:00) → 支付(次日03:00) | 跨度19h,仍在24h内 |
| u_03 | 放弃支付 | 注册(09:00) → 浏览(09:30) → 下单(10:00) → (无) | 下单后流失 |
| u_04 | 支付超时 | 注册(09:00) → 浏览(09:30) → 下单(10:00) → 支付(次日11:00) | 支付了,但从注册到支付间隔26h |
| u_05 | 放弃下单 | 注册(10:00) → 浏览(10:30) → (无) | 浏览后流失 |
| u_06 | 仅注册 | 注册(11:00) → (无) | 直接离开 |
| u_07 | 犹豫不决 | 注册(12:00) → 浏览(12:30) → 浏览(14:00) → 浏览(16:00) | 反复看但不下单 |
| u_08 | 全流程多浏览 | 注册(08:00) → 浏览×3 → 下单(14:00) → 浏览(15:00) → 支付(18:00) | 完整漏斗,中间有大量浏览 |
完整 INSERT 语句:
-- u_01: 完整漏斗,1h 内完成 (level=4)
INSERT INTO user_behavior (user_id, event_type, event_time) VALUES
('u_01', 'register', '2026-06-05 08:00:00'),
('u_01', 'view_product', '2026-06-05 08:30:00'),
('u_01', 'create_order', '2026-06-05 08:45:00'),
('u_01', 'pay_success', '2026-06-05 09:00:00');
-- u_02: 完整漏斗,跨度 19h (level=4, 仍在 24h 窗口内)
INSERT INTO user_behavior (user_id, event_type, event_time) VALUES
('u_02', 'register', '2026-06-05 08:00:00'),
('u_02', 'view_product', '2026-06-05 12:00:00'),
('u_02', 'create_order', '2026-06-05 20:00:00'),
('u_02', 'pay_success', '2026-06-06 03:00:00');
-- u_03: 创建订单但未支付 (level=3)
INSERT INTO user_behavior (user_id, event_type, event_time) VALUES
('u_03', 'register', '2026-06-05 09:00:00'),
('u_03', 'view_product', '2026-06-05 09:30:00'),
('u_03', 'create_order', '2026-06-05 10:00:00');
-- u_04: 支付了但超出 24h 窗口 (level=3)
-- 从 register(09:00) 到 pay_success(次日11:00) 间隔 26h
INSERT INTO user_behavior (user_id, event_type, event_time) VALUES
('u_04', 'register', '2026-06-05 09:00:00'),
('u_04', 'view_product', '2026-06-05 09:30:00'),
('u_04', 'create_order', '2026-06-05 10:00:00'),
('u_04', 'pay_success', '2026-06-06 11:00:00');
-- u_05: 浏览商品但未下单 (level=2)
INSERT INTO user_behavior (user_id, event_type, event_time) VALUES
('u_05', 'register', '2026-06-05 10:00:00'),
('u_05', 'view_product', '2026-06-05 10:30:00');
-- u_06: 仅注册未浏览 (level=1)
INSERT INTO user_behavior (user_id, event_type, event_time) VALUES
('u_06', 'register', '2026-06-05 11:00:00');
-- u_07: 重复浏览但未下单 (level=2)
INSERT INTO user_behavior (user_id, event_type, event_time) VALUES
('u_07', 'register', '2026-06-05 12:00:00'),
('u_07', 'view_product', '2026-06-05 12:30:00'),
('u_07', 'view_product', '2026-06-05 14:00:00'),
('u_07', 'view_product', '2026-06-05 16:00:00');
-- u_08: 完整漏斗,中间穿插多次浏览 (level=4)
INSERT INTO user_behavior (user_id, event_type, event_time) VALUES
('u_08', 'register', '2026-06-05 08:00:00'),
('u_08', 'view_product', '2026-06-05 08:30:00'),
('u_08', 'view_product', '2026-06-05 09:00:00'),
('u_08', 'view_product', '2026-06-05 10:00:00'),
('u_08', 'create_order', '2026-06-05 14:00:00'),
('u_08', 'view_product', '2026-06-05 15:00:00'),
('u_08', 'pay_success', '2026-06-05 18:00:00');数据就绪,开搞。
三、windowFunnel 初体验
语法长这样:
windowFunnel(window_size)(timestamp, cond1, cond2, cond3, ...)window_size:时间窗口,单位秒。86400 = 24 小时timestamp:事件发生时间cond1, cond2, ...:按顺序匹配的条件,比如event_type = 'register'
规则其实很简单:对每个用户,从第一个条件匹配到的那条事件开始计时,顺着时间往后找第二个条件、第三个条件……所有步骤必须发生在 window_size 秒之内。
先跑一版查询看看
SELECT
level,
count() AS user_count
FROM (
SELECT
user_id,
windowFunnel(86400)(event_time,
event_type = 'register',
event_type = 'view_product',
event_type = 'create_order',
event_type = 'pay_success'
) AS level
FROM user_behavior
WHERE event_time >= '2026-06-01' AND event_time < '2026-06-12'
GROUP BY user_id
)
GROUP BY level
ORDER BY level ASC;结果出来了:
| level | user_count |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 2 |
| 4 | 3 |
看到这个结果你的第一反应可能是:啥意思?
windowFunnel 到底返回了什么
windowFunnel 对每个用户返回一个整数——这个人按顺序走到了第几步。注意,是“止步于第几步”,不是“经过了第几步”。这是个关键区别,很多第一次用的人会搞混。
一个一个看:
| 用户 | 行为链 | windowFunnel 判断 | level |
|---|---|---|---|
| u_01 | 注册→浏览→下单→支付(全部1h内) | 第4步在窗口内完成 | 4 |
| u_02 | 注册→浏览→下单→支付(跨度19h) | 第4步在24h窗口内 | 4 |
| u_03 | 注册→浏览→下单(无支付) | 第3步匹配,第4步不存在 | 3 |
| u_04 | 注册→浏览→下单→支付(注册到支付26h) | 第3步匹配,第4步超出24h窗口被忽略 | 3 |
| u_05 | 注册→浏览(无下单) | 第2步匹配,第3步不存在 | 2 |
| u_06 | 注册(无浏览) | 第1步匹配,第2步不存在 | 1 |
| u_07 | 注册→浏览×3 | 第2步匹配,第3步不存在 | 2 |
| u_08 | 注册→浏览×3→下单→浏览→支付 | 全部4步在10h窗口内完成 | 4 |
看懂了没?
level=1 只有1人,不是说 8 个人里只有 1 个注册了——而是这 8 个人里只有 1 个人走到注册就停了(u_06)。剩下 7 个都往下走了,被归到了更高的 level 里。
GROUP BY level 的含义:
- level 4:3 人走到最后,支付了
- level 3:2 人卡在下单这一步
- level 2:2 人卡在浏览这一步
- level 1:1 人卡在注册这一步
怎么从卡住人数反推漏斗?往上加就行:
支付成功 = level 4 = 3人
创建订单 = level 3 + level 4 = 2+3 = 5人
浏览商品 = level 2 + 3 + 4 = 2+2+3 = 7人
注册 = level 1 + 2 + 3 + 4 = 1+2+2+3 = 8人所以漏斗长这样:8 → 7 → 5 → 3。每步转化率:87.5% → 71.4% → 60.0%。
四、直接拿到累积值,别自己加
上面那种“卡住人数”虽然忠实反映了 windowFunnel 的原始语义,但做报表的时候不够直观。能不能让查询直接吐出累积人数?
用 ARRAY JOIN 把每个用户的 level 展开:
SELECT
step,
count() AS user_count
FROM (
SELECT
user_id,
windowFunnel(86400)(event_time,
event_type = 'register',
event_type = 'view_product',
event_type = 'create_order',
event_type = 'pay_success'
) AS level
FROM user_behavior
WHERE event_time >= '2026-06-01' AND event_time < '2026-06-12'
GROUP BY user_id
)
ARRAY JOIN [1,2,3,4] AS step
WHERE level >= step
GROUP BY step
ORDER BY step ASC;结果:
| step | user_count | 含义 |
|---|---|---|
| 1 | 8 | 8 人注册 |
| 2 | 7 | 7 人浏览了商品 |
| 3 | 5 | 5 人创建了订单 |
| 4 | 3 | 3 人支付成功 |
这样就直接拿到了漏斗累积值,不用自己手动加了。
这查询在干吗?
ARRAY JOIN 就是把每个用户的一行拆成多行:
拿 u_01 来说,原始:user_id='u_01', level=4
ARRAY JOIN [1,2,3,4] AS step 展开:
u_01, level=4, step=1 → level >= 1 ✓ 留下
u_01, level=4, step=2 → level >= 2 ✓ 留下
u_01, level=4, step=3 → level >= 3 ✓ 留下
u_01, level=4, step=4 → level >= 4 ✓ 留下
拿 u_06 来说,原始:user_id='u_06', level=1
ARRAY JOIN [1,2,3,4] AS step 展开:
u_06, level=1, step=1 → level >= 1 ✓ 留下
u_06, level=1, step=2 → level >= 2 ✗ 干掉
u_06, level=1, step=3 → level >= 3 ✗ 干掉
u_06, level=1, step=4 → level >= 4 ✗ 干掉逻辑就是:你走到了 level N,说明你必然经过了 step 1 到 step N。GROUP BY step 一数,就是漏斗本来的样子。
另一个路子:sumIf 条件聚合
ARRAY JOIN 的思路是先展开再过滤。8 个人展开成 32 行,问题不大。但如果是千万级用户呢?
1000 万用户 × 4 个步骤 = 4000 万行(展开后)数据量大起来,行爆炸对内存就不太友好了。这时候可以用 sumIf——直接在聚合结果上做条件计数,一行都不膨胀:
SELECT
sumIf(1, level >= 1) AS step1_register,
sumIf(1, level >= 2) AS step2_view_product,
sumIf(1, level >= 3) AS step3_create_order,
sumIf(1, level >= 4) AS step4_pay_success
FROM (
SELECT
user_id,
windowFunnel(86400)(event_time,
event_type = 'register',
event_type = 'view_product',
event_type = 'create_order',
event_type = 'pay_success'
) AS level
FROM user_behavior
WHERE event_time >= '2026-06-01' AND event_time < '2026-06-12'
GROUP BY user_id
);结果:
| step1_register | step2_view_product | step3_create_order | step4_pay_success |
|---|---|---|---|
| 8 | 7 | 5 | 3 |
sumIf(1, condition) 就是 countIf():条件为真加 1,否则加 0。子查询输出 8 行(每个用户一行),外层在 8 行上做 4 次条件判断,没有行膨胀。
如果需要每步一行的格式给前端用,套个 UNION ALL 就好:
SELECT '注册' AS step, sumIf(1, level >= 1) AS user_count FROM subquery
UNION ALL
SELECT '浏览商品', sumIf(1, level >= 2) FROM subquery
UNION ALL
SELECT '创建订单', sumIf(1, level >= 3) FROM subquery
UNION ALL
SELECT '支付成功', sumIf(1, level >= 4) FROM subquery;两种方案怎么选
| 方案 | 中间行数 | 内存 | 适用规模 | 写起来 |
|---|---|---|---|---|
| ARRAY JOIN + GROUP BY | 用户数 × 步数 | 较高 | 百万级以内 | 直观 |
| sumIf / countIf | 用户数 | 低 | 千万级以上 | 略啰嗦 |
| UNION ALL + sumIf | 用户数 × 查询次数 | 低 | 千万级以上 | 最啰嗦 |
日常写探索查询用 ARRAY JOIN,思路清晰好调。上线面对大量数据切成
sumIf。两个方案结果一模一样,先用 ARRAY JOIN 把逻辑验证过,切过去放心。
五、u_04 的巧妙之处——时间窗口到底是什么
注意 u_04:他注册、浏览、下单、支付,四步全走完了,但 windowFunnel 只给了 level=3。为什么?
u_04: 注册(06-05 09:00) → 浏览(06-05 09:30) → 下单(06-05 10:00) → 支付(06-06 11:00)
^^^^^^^^^^^^^^^^
距注册已经 26 小时了windowFunnel(86400) 的窗口是 86400 秒 = 24 小时。窗口从第一步匹配到的时间起算——u_04 的窗口从 06-05 09:00 开始,06-06 09:00 结束。他的支付发生在 06-06 11:00,超了 2 小时,所以没算进去。
这个案例其实挺有意思的:u_04 愿意付钱,只是决策周期长了一点。如果把窗口从 24h 扩到 48h(windowFunnel(172800)),他就是 level=4 了。窗口设多大,得看你的业务场景——用户从注册到转化,正常的周期是多长?设短了漏人,设长了稀释漏斗的区分度。
六、windowFunnel 到底好在哪
跟手写 SQL 比一下:
| 方案 | 代码量 | 复杂度 | 性能 |
|---|---|---|---|
| 手写多步 JOIN + 时间差 | ~50行 | 得写一堆子查询和窗口函数 | 差 |
| windowFunnel | ~10行 | 一行函数 | 向量化执行,快 |
不只电商漏斗,能用的地方还挺多:
- 用户路径分析:首页→搜索→详情→加购→下单
- 新手引导:打开App→注册→完善资料→首次发帖
- 活动效果:收到推送→点击→进入活动→参与→分享
- 售后流程:申请退款→审核→退款到账
顺带一提,ClickHouse 还有一个
sequenceMatch函数,能做比 windowFunnel 更灵活的模式匹配——比如“浏览了A但没买B”这类否定条件。本文不展开,后续另开一篇详细讲。
七、mode 参数:让漏斗更“严格”
前面用的都是默认模式。windowFunnel 的完整签名其实有三个参数:
windowFunnel(window_size, mode, auto_fix)(timestamp, cond1, cond2, ...)mode:事件匹配模式,控制匹配链条的严格程度auto_fix:布尔值,设1时自动修时钟漂移导致的乱序时间戳(默认0,一般不用开)
mode 有三个值,区别在于对“中间噪音”的容忍程度。
7.1 strict_deduplication(默认)
无关事件直接跳过。 最宽松,也是前面所有例子用的模式。
u_08: register(08:00) → view(08:30) → view(09:00) → view(10:00) → order(14:00) → pay(18:00)链条匹配:register(08:00) → view(08:30) → order(14:00) → pay(18:00) → level 4
中间那几次多余的浏览直接忽略。只要按顺序找到每个条件的第一次命中,链条就成立。
7.2 strict_order
链条中间不能出现“回退事件”。 比默认严格——在某步之后如果又冒出前面的步骤事件,链条就断了。
假设有个用户 u_09,注册了两次(可能是 bug 或者手滑):
u_09: register(08:00) → view(09:00) → register(10:00) → order(11:00) → pay(12:00)| 模式 | 匹配过程 | level |
|---|---|---|
| strict_deduplication | register(08:00) → view(09:00) → |
4 |
| strict_order | register(08:00) → view(09:00) → register(10:00) 又来了个 register,链条断了 | 2 |
strict_order 的逻辑:正在找 create_order 呢,结果冒出一个 register(步骤 1 的事件),说明用户行为回退了,漏斗不成立。
7.3 strict_increase
strict_order 的基础上,还要时间戳严格递增。 最严的模式。
现实中可能会遇到这种情况——同一秒来了多个事件(批量导入、客户端时钟问题):
u_10: register(08:00) → view(09:00) → order(09:00) → pay(10:00)
^^^^^^^^^^^^^^^^
view 和 order 时间戳一样| 模式 | 匹配过程 | level |
|---|---|---|
| strict_order | register(08:00) → view(09:00) → order(09:00 同时间戳放行) → pay(10:00) | 4 |
| strict_increase | register(08:00) → view(09:00) → order(09:00) 时间戳没递增,断了 | 2 |
模式速查
| 模式 | 中间无关事件 | 前序事件回退 | 相同时间戳 | 什么时候用 |
|---|---|---|---|---|
| strict_deduplication | 放过 | 放过 | 放过 | 绝大多数场景,默认用这个 |
| strict_order | 放过 | 拦住 | 放过 | 不能容忍行为回退 |
| strict_increase | 放过 | 拦住 | 拦住 | 排查数据质量问题、最严格场景 |
SQL 怎么写
-- 默认模式(不写 mode 就行)
SELECT user_id, windowFunnel(86400)(event_time,
event_type = 'register',
event_type = 'view_product',
event_type = 'create_order',
event_type = 'pay_success'
) AS level
FROM user_behavior
GROUP BY user_id;
-- 严格顺序
SELECT user_id, windowFunnel(86400, 'strict_order')(event_time,
event_type = 'register',
event_type = 'view_product',
event_type = 'create_order',
event_type = 'pay_success'
) AS level
FROM user_behavior
GROUP BY user_id;
-- 严格递增 + 开启时钟修正
SELECT user_id, windowFunnel(86400, 'strict_increase', 1)(event_time,
event_type = 'register',
event_type = 'view_product',
event_type = 'create_order',
event_type = 'pay_success'
) AS level
FROM user_behavior
GROUP BY user_id;九成场景默认模式够用了。
strict_order在你确实需要验证“用户没有倒退”的时候才开。strict_increase基本是排查数据问题时候的杀手锏。
八、可视化实战
SQL 查出来数据了,最后一步得让老板看到能看得懂的图表。数据扔进漏斗图长这样:
┌─────────────────────────────────────────┐
│ 注册 8 人 │
│ 87.5% │
├─────────────────────────────────┤
│ 浏览商品 7 人 │
│ 71.4% │
├──────────────────────────┤
│ 创建订单 5 人 │
│ 60.0% │
├────────────────────┤
│ 支付成功 3 人 │
└────────────────────┘下面来看看怎么把这个数据变成一个实际可用的系统。
8.1 后端 API
封一个接口,把 ARRAY JOIN 查询的结果吐成 JSON:
GET /api/funnel{
"steps": [
{ "name": "注册", "value": 8, "rate": "100.0%" },
{ "name": "浏览商品", "value": 7, "rate": "87.5%" },
{ "name": "创建订单", "value": 5, "rate": "71.4%" },
{ "name": "支付成功", "value": 3, "rate": "60.0%" }
]
}Go、Ruby、Python、Node 都行,逻辑一样:执行 ClickHouse 查询,把 step 和 user_count 一对一对映射成 name 和 value,顺手算一下每步转化率。
8.2 前端 ECharts 漏斗图
ECharts 自带漏斗图类型,几行代码出图:
<script src="https://cdn.jsdelivr.net/npm/echarts@5.5.0/dist/echarts.min.js"></script>
<div id="chart" style="width:600px;height:400px"></div>
<script>
const data = [
{ name: '注册', value: 8 },
{ name: '浏览商品', value: 7 },
{ name: '创建订单', value: 5 },
{ name: '支付成功', value: 3 }
];
const chart = echarts.init(document.getElementById('chart'));
chart.setOption({
series: [{
type: 'funnel',
data,
label: { show: true, position: 'inside' }
}]
});
</script>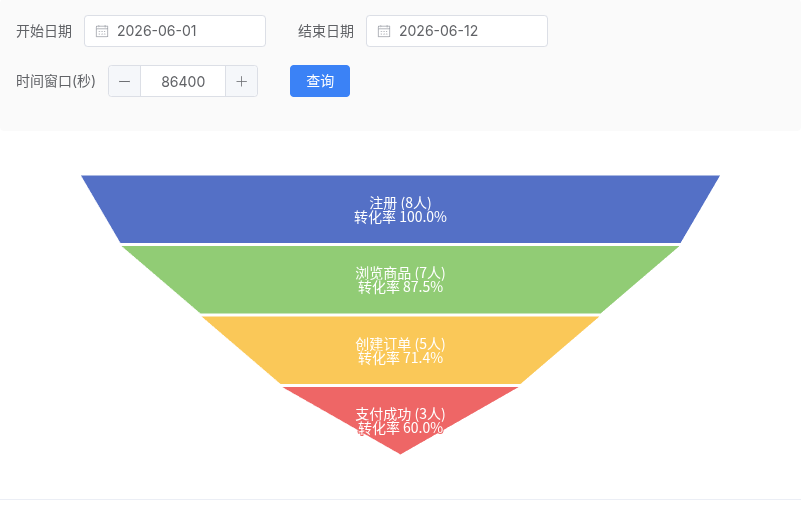
保存成 funnel.html 打开就能看。实际项目里把 data 换成 fetch('/api/funnel') 就接上了。
8.3 多维度对比
业务上经常需要按渠道拆开看——比如微信推广 vs 抖音推广的漏斗对比:
SELECT
channel,
step,
count() AS user_count
FROM (
SELECT
user_id,
channel,
windowFunnel(86400)(event_time,
event_type = 'register',
event_type = 'view_product',
event_type = 'create_order',
event_type = 'pay_success'
) AS level
FROM user_behavior
WHERE event_time >= '2026-06-01' AND event_time < '2026-06-12'
GROUP BY user_id, channel
)
ARRAY JOIN [1,2,3,4] AS step
WHERE level >= step
GROUP BY channel, step
ORDER BY channel, step;前端用 ECharts 的多个漏斗并排,或者用 dataset + transform 切换维度,哪个渠道转化好一目了然。
8.4 整条链路
┌──────────┐ ┌───────────┐ ┌──────────┐ ┌──────────┐
│ 行为埋点 │ → │ ClickHouse│ → │ 后端 API │ → │ 前端图表 │
│ (SDK采集)│ │windowFunnel│ │(/api/ │ │(ECharts) │
│ │ │ + ARRAY │ │ funnel) │ │ │
│ │ │ JOIN │ │ │ │ │
└──────────┘ └───────────┘ └──────────┘ └──────────┘从埋点入库到可视化,核心查询就一行 windowFunnel,前后端加起来也不过百来行。现代分析型数据库配上成熟的图表库,做漏斗真的没那么费劲。
九、总结
windowFunnel返回的是每个用户的最高到达层级,不是累积人数——这个一开始容易搞混- 漏斗累积值 = 各层级止步人数从高到低累加,或者直接用 ARRAY JOIN
- 数据量大时
sumIf替代 ARRAY JOIN,避免行膨胀 - 时间窗口从第一步事件的时间戳起算,不是查询的时间范围
- 窗口大小看业务,设短了漏人,设长了没区分度
8 个用户,29 条事件,一行 windowFunnel,整个漏斗清清楚楚。这就是为什么 ClickHouse 做分析爽。